Недомыслие user info php. Простой RESTful-сервис на нативном PHP. Использование элементов массива $_SERVER
Те, кто более-менее серьёзно изучал PHP знают, что существует один очень полезный глобальный массив в PHP , который называется $_SERVER . И вот хотелось бы в этой статье разобрать самые популярные ключи и их значения в этом массиве, так как их знание просто обязательно даже для начинающего PHP-программиста .
Прежде чем приступить к глобальному массиву $_SERVER в PHP , сразу сделаю небольшую подсказку. Есть замечательная функция, встроенная в PHP , которая называется phpinfo() . Давайте сразу приведу пример её использования:
phpinfo();
?>
В результате выполнения этого просто скрипта Вы увидите огромную таблицу с различными настройками интерпритатора PHP , в том числе, ближе к концу будет таблица значений глобального массива $_SERVER . Там будут перечислены все ключи и все соответствующие им значения. Чем это может Вам помочь? А тем, что если Вам потребуется то или иное значение, и Вы забудете, как называется ключ, то с помощью функции phpinfo() Вы можете всегда вспомнить его название. В общем, Вы выполните этот скрипт и сразу меня поймёте.
А теперь давайте перейдём к самым популярным ключам массива $_SERVER :
- HTTP_USER_AGENT - этот ключ позволяет узнать характеристику клиента. В большинстве случаев, это, безусловно, браузер, однако, не всегда. И опять же, если браузер, то какой, вот в этой переменной об этом можно и узнать.
- HTTP_REFERER - содержит абсолютный путь к тому файлу (PHP-скрипт , HTML-страница ), с которого перешли на данный скрипт. Грубо говоря, откуда пришёл клиент.
- SERVER_ADDR - IP-адрес сервера.
- REMOTE_ADDR - IP-адрес клиента.
- DOCUMENT_ROOT - физический путь к корневой директории сайта. Это опция задаётся через конфигурационный файл сервера Apache .
- SCRIPT_FILENAME - физический путь к вызванному скрипту.
- QUERY_STRING - весьма полезное значение, которое позволяет получить строку с запросом, а дальше можно заниматься парсингом этой строки.
- REQUEST_URI - ещё более полезное значение, которое содержит не только сам запрос, но и вместе с ним относительный путь к вызываемому скрипту от корня. Это очень часто используется для удаления дублирования с index.php , то есть когда у нас такой URL : "http://mysite.ru/index.php " и "http://mysite.ru/ " ведут на одну страницу, а URLы разные, следовательно, дублирование, что плохо скажется на поисковой оптимизации. И вот с помощью REQUEST_URI мы можем определить: с index.php или нет был вызван скрипт. И можем сделать редирект с index.php (если он присутствовал в REQUEST_URI ) на без index.php . В результате, при передаче такого запроса: "http://mysite.ru/index.php?id=5 ", у нас будет происходить редирект на URL : "http://mysite.ru/?id=5 ". То есть мы избавились от дублирования, удалив из URL этот index.php .
- SCRIPT_NAME - относительный путь к вызываемому скрипту.
Пожалуй, это все элементы глобального массива $_SERVER в PHP , которые используются регулярно. Их надо знать и уметь использовать, когда это необходимо.
Возможные атаки
Использование PHP как бинарного CGI-приложения является одним из вариантов, когда по каким-либо причинам нежелательно интегрировать PHP в веб-сервер (например Apache) в качестве модуля, либо предполагается использование таких утилит, как chroot и setuid для организации безопасного окружения во время работы скриптов. Такая установка обычно сопровождается копированием исполняемого файла PHP в директорию cgi-bin веб-сервера. CERT (организация, следящая за угрозами безопасности) CA-96.11 рекомендует не помещать какие-либо интерпретаторы в каталог cgi-bin. Даже если PHP используется как самостоятельный интерпретатор, он спроектирован так, чтобы предотвратить возможность следующих атак:
Доступ к системным файлам: http://my.host/cgi-bin/php?/etc/passwd
Данные, введенные в строке запроса (URL) после вопросительного знака, передаются интерпретатору как аргументы командной строки согласно CGI протоколу. Обычно интерпретаторы открывают и исполняют файл, указанный в качестве первого аргумента.
В случае использования PHP посредством CGI-протокола он не станет интерпретировать аргументы командной строки.
Доступ к произвольному документу на сервере: http://my.host/cgi-bin/php/secret/doc.html
Согласно общепринятому соглашению часть пути в запрошенной странице, которая расположена после имени выполняемого модуля PHP, /secret/doc.html , используется для указания файла, который будет интерпретирован как CGI-программа Обычно, некоторые конфигурационные опции веб-сервера (например, Action для сервера Apache) используются для перенаправления документа, к примеру, для перенаправления запросов вида http://my.host/secret/script.php интерпретатору PHP. В таком случае веб-сервер вначале проверяет права доступа к директории /secret , и после этого создает перенаправленный запрос http://my.host/cgi-bin/php/secret/script.php . К сожалению, если запрос изначально задан в полном виде, проверка на наличие прав для файла /secret/script.php не выполняется, она происходит только для файла /cgi-bin/php . Таким образом, пользователь имеет возможность обратиться к /cgi-bin/php , и, как следствие, к любому защищенному документу на сервере.
В PHP, указывая во время компиляции опцию --enable-force-cgi-redirect , а таке опции doc_root и user_dir во время выполнения скрипта, можно предотвратить подобные атаки для директорий с ограниченным доступом. Более детально приведенные опции, а также их комбинации будут рассмотрены ниже.
Вариант 1: обслуживаются только общедоступные файлы
В случае, если на вашем сервере отсутствуют файлы, доступ к которым ограничен паролем либо фильтром по IP-адресам, нет никакой необходимости использовать данные опции. Если ваш веб-сервер не разрешает выполнять перенаправления либо не имеет возможности взаимодействовать с исполняемым PHP-модулем на необходимом уровне безопасности, вы можете использовать опцию --enable-force-cgi-redirect во время сборки PHP. Но при этом вы должны убедиться, что альтернативные способы вызова скрипта, такие как непосредственно вызов http://my.host/cgi-bin/php/dir/script.php либо с переадресацией http://my.host/dir/script.php , недоступны.
В веб-сервере Apache перенаправление может быть сконфигурировано при помощи директив AddHandler и Action (описано ниже).
Вариант 2: использование --enable-force-cgi-redirect
Эта опция, указываемая во время сборки PHP, предотвращает вызов скриптов непосредственно по адресу вида http://my.host/cgi-bin/php/secretdir/script.php . Вместо этого, PHP будет обрабатывать пришедший запрос только в том случае, если он был перенаправлен веб-сервером.
Обычно перенаправление в веб-сервере Apache настраивается при помощи следующих опций:
| Action php-script /cgi-bin/php AddHandler php-script .php |
Эта опция проверена только для веб-сервера Apache, ее работа основывается на установке в случае перенаправления нестандартной переменной REDIRECT_STATUS , находящейся в CGI-окружении. В случае, если ваш веб-сервер не предоставляет возможности однозначно идентифицировать, является ли данный запрос перенаправленным, вы не можете использовать описываемую в данном разделе опцию и должны воспользоваться любым другим методом работы с CGI-приложениями.
Вариант 3: использование опций doc_root и user_dir
Размещение динамического контента, такого как скрипты либо любые другие исполняемые файлы, в директории веб-сервера делает его потенциально опасным. В случае, если в конфигурации сервера допущена ошибка, возможна ситуация, когда скрипты не выполняются, а отображаются в браузере, как обычные HTML-документы, что может привести к утечке конфиденциальной информации (например, паролей), либо информации, являющейся интеллектуальной собственностью. Исходя из таких соображений, многие системные администраторы предпочитают использовать для хранения скриптов отдельную директорию, работая со всеми размещенными в ней файлами по CGI-интерфейсу.
В случае, если невозможно гарантировать, что запросы не перенаправляются, как было показано в предыдущем разделе, необходимо указывать переменную doc_root, которая отличается от корневой директории веб-документов.
Вы можете установить корневую директорию для PHP-скриптов, настроив параметр doc_root в конфигурационном файле , либо установив переменную окружения PHP_DOCUMENT_ROOT . В случае, если PHP используется посредством CGI, полный путь к открываемому файлу будет построен на основании значения переменной doc_root и указанного в запросе пути. Таким образом, вы можете быть уверены, что скрипты будут выполняться только внутри указанной вами директории (кроме директории user_dir , которая описана ниже).
Еще одна используемая при настройке безопасности опция - user_dir . В случае, если переменная user_dir не установлена, путь к открываемому файлу строится относительно doc_root . Запрос вида http://my.host/~user/doc.php приводит к выполнению скрипта, находящегося не в домашнем каталоге соответствующего пользователя, а находящегося в подкаталоге doc_root скрипта ~user/doc.php (да, имя директории начинается с символа ~).
Но если переменной public_php присвоено значение, например, http://my.host/~user/doc.php , тогда в приведенном выше примере будет выполнен скрипт doc.php , находящийся в домашнем каталоге пользователя, в директории public_php . Например, если домашний каталог пользователя /home/user , будет выполнен файл /home/user/public_php/doc.php .
Установка опции user_dir происходит независимо от установки doc_root , таким образом вы можете контролировать корневую директорию веб-сервера и пользовательские директории независимо друг от друга.
Вариант 4: PHP вне дерева веб-документов
Один из способов существенно повысить уровень безопасности - поместить исполняемый модуль PHP вне дерева веб-документов, например в /usr/local/bin . Единственным недостатком такого подхода является то, что первая строка каждого скрипта должна иметь вид:
| #!/usr/local/bin/php |
Также необходимо сделать все файлы скриптов исполняемыми. Таким образом, скрипт будет рассматриваться так же, как и любое другое CGI-приложение, написанное на Perl, sh или любом другом скриптовом языке, который использует дописывание #! в начало файла для запуска самого себя.
Что бы внутри скрипта вы могли получить корректные значения переменных PATH_INFO и PATH_TRANSLATED , PHP должен быть сконфигурирован с опцией --enable-discard-path .
| <<< Назад | Содержание | Вперед >>> |
| Есть еще вопросы или что-то непонятно - добро пожаловать на наш | |
|
|
февраль 5 , 2017
Я не знаю ни одного php-фреймворка. Это печально и стыдно, но законом пока не запрещено. А при этом поиграться с REST API хочется. Проблема в том, что php по умолчанию поддерживает только $_GET и $_POST. А для RESTful-сервиса надобно уметь работать еще и с PUT, DELETE и PATCH. И не очень очевидно, как культурно обработать множество запросов вида GET http://site.ru/users, DELETE http://site.ru/goods/5 и прочего непотребства. Как завернуть все подобные запросы в единую точку, универсально разобрать их на части и запустить нужный код для обработки данных?
Почти любой php-фреймворк умеет делать это из коробки. Например, Laravel, где роутинг реализован понятно и просто. Но что если нам не нужно прямо сейчас заниматься изучением новой большой темы, а хочется просто быстро завести проект с поддержкой REST API? Об этом и пойдет речь в статье.
Что должен уметь наш RESTful-сервис?
1. Поддерживать все 5 основных типов запросов: GET, POST, PUT, PATCH, DELETE.
2. Разруливать разнообразные маршруты вида
POST /goods
PUT /goods/{goodId}
GET /users/{userId}/info
и прочие сколь угодно длинные цепочки.
Внимание: это статья не про основы REST API
Я предполагаю, что Вы уже знакомы с REST-подходом и понимаете, как это работает.
Если нет, то в интернетах много замечательных статей по основам REST -
я не хочу дублировать их, моя идея - показать, как с REST работать на практике.
Какой функционал мы будем поддерживать?
Рассмотрим 2 сущности - товары и пользователи.
Для товаров возможности следующие:
- 1. GET /goods/{goodId} — Получение информации о товаре
- 2. POST /goods — Добавление нового товара
- 3. PUT /goods/{goodId} — Редактирование товара
- 4. PATCH /goods/{goodId} — Редактирование некоторых параметров товара
- 5. DELETE /goods/{goodId} — Удаление товара
По пользователям для разнообразия рассмотрим несколько вариантов с GET
- 1. GET /users/{userId} — Полная информация о пользователе
- 2. GET /users/{userId}/info — Только общая информация о пользователе
- 3. GET /users/{userId}/orders — Список заказов пользователя
Как это заработает на нативном PHP?
Первое, что мы сделаем - это настроим.htaccess так, чтобы все запросы перенаправлялись на файл index.php. Именно он и будет заниматься извлечением данных.
Второе - определимся, какие данные нам нужны и напишем код для их получения - в index.php.
Нас интересуют 3 типа данных:
- 1. Метод запроса (GET, POST, PUT, PATCH или DELETE)
- 2. Данные из URL-a, например, users/{userId}/info - нужны все 3 параметра
- 3. Данные из тела запроса
.htaccess
Создадим в корне проекта файл.htaccess
RewriteEngine On RewriteCond %{REQUEST_FILENAME} !-f RewriteRule ^(.+)$ index.php?q=$1
Этими загадочными строками мы повелеваем делать так:
1 - направить все запросы любого вида на царь-файл index.php
2 - сделать строку в URL-е доступной в index.php в get-параметре q.
То есть данные из URL-а вида /users/{userId}/info
мы достанем из $_GET["q"].
index.php
Рассмотрим index.php строка за строкой. Для начала получим метод запроса.
// Определяем метод запроса $method = $_SERVER["REQUEST_METHOD"];
Затем данные из тела запроса
// Получаем данные из тела запроса $formData = getFormData($method);
Для GET и POST легко вытащить данные из соответствующих массивов $_GET и $_POST. А вот для остальных методов нужно чуть извратиться. Код для них вытаскивается из потока php://input , код легко гуглится, я всего лишь написал общую обертку - функцию getFormData($method)
// Получение данных из тела запроса function getFormData($method) { // GET или POST: данные возвращаем как есть if ($method === "GET") return $_GET; if ($method === "POST") return $_POST; // PUT, PATCH или DELETE $data = array(); $exploded = explode("&", file_get_contents("php://input")); foreach($exploded as $pair) { $item = explode("=", $pair); if (count($item) == 2) { $data = urldecode($item); } } return $data; }
То есть мы получили нужные данные, скрыв все детали в getFormData - ну и отлично. Переходим к самому интересному - роутингу.
// Разбираем url $url = (isset($_GET["q"])) ? $_GET["q"] : ""; $url = rtrim($url, "/"); $urls = explode("/", $url);
Выше мы узнали, что.htaccess подложит нам параметры из URL-a в q-параметр массива $_GET. То есть в $_GET["q"] попадет примерно такая строка: users/10 . Независимо от того, каким методом мы запрос дергаем.
А explode("/", $url)
преобразует нам эту строку в массив, с которым уже можно работать.
Таким образом, составляйте сколько угодно длинные цепочки запросов, например,
GET /goods/page/2/limit/10/sort/price_asc
И будьте уверены, получите массив
$urls = array("goods", "page", "2", "limit", "10", "sort", "price_asc");
Теперь у нас есть все данные, нужно сделать с ними что-нибудь полезное. А сделают это всего лишь 4 строки кода
// Определяем роутер и url data $router = $urls; $urlData = array_slice($urls, 1); // Подключаем файл-роутер и запускаем главную функцию include_once "routers/" . $router . ".php"; route($method, $urlData, $formData);
Улавливаете? Мы заводим папку routers, в которую складываем файлы, манипулирующие одной сущностью: товарами или пользователями. При этом договариваемся, что название файлов совпадают с первым параметром в urlData - он и будет роутером, $router. А из urlData этот роутер нужно убрать, он нам больше не нужен и используется только для подключения нужного файла. array_slice($urls, 1) и вытащит нам все элементы массива, кроме первого.
Теперь осталось подключить нужный файл-роутер и запустить функцию route с тремя параметрами. Что же это за function route? Условимся, что в каждом файле-роутере будет определена такая функция, которая по входным параметрам определит, какое действие инициировал пользователь, и выполнит нужный код. Сейчас это станет понятнее. Рассмотрим первый запрос - получение данных о товаре.
GET /goods/{goodId}
Файл routers/goods.php
// Роутер function route($method, $urlData, $formData) { // Получение информации о товаре // GET /goods/{goodId} if ($method === "GET" && count($urlData) === 1) { // Получаем id товара $goodId = $urlData; // Вытаскиваем товар из базы... // Выводим ответ клиенту echo json_encode(array("method" => "GET", "id" => $goodId, "good" => "phone", "price" => 10000)); return; } // Возвращаем ошибку header("HTTP/1.0 400 Bad Request"); echo json_encode(array("error" => "Bad Request")); }
Содержимое файла - это одна большая функция route, которая в зависимости от переданных параметров выполняет нужные действия. Если метод GET и в urlData передан 1 параметр (goodId), то это запрос о получении данных о товаре.
Внимание: пример очень упрощенный
В реале, конечно же, нужно дополнительно проверять входные параметры, например, что goodId - это число.
Вместо того, чтобы писать код здесь, Вы, вероятно, подключите нужный класс.
И для получения товара создадите объект оного класса и вызовете у него какой-то метод.
А может быть, передадите управление какому-то контроллеру, который уже озаботится инициализацией нужных моделей.
Вариантов много, мы рассматриваем только общую структуру кода.
В ответе клиенту мы выводим нужные данные: название товара и его цену. id товара и метод в реальном приложении совершенно не обязательны. Покажем их только, чтобы убедится, что вызывается нужный метод с правильными параметрами.
Давайте попробуем на примере: откройте консоль браузера и выполните код
$.ajax({url: "/examples/rest/goods/10", method: "GET", dataType: "json", success: function(response){console.log("response:", response)}})
Код отправит запрос на сервер, где я развернул подобное приложение и выведет ответ.
Убедитесь, что интересующий наш маршрут /goods/10
действительно отработал.
На вкладке Network Вы заметите такой же запрос.
И да, /examples/rest - это корневой путь нашего тестового приложения на сайт
Если Вам привычнее пользоваться curl-ом в консоли, то запустите в терминале это - ответ будет тот же самый, да еще и с заголовками от сервера.
Curl -X GET https://сайт/examples/rest/goods/10 -i
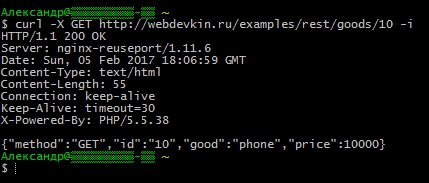
В конце функции мы написали такой код.
// Возвращаем ошибку header("HTTP/1.0 400 Bad Request"); echo json_encode(array("error" => "Bad Request"));
Он значит, что если мы ошиблись с параметрами или запрашиваемый маршрут не определен, то вернем клиенту 400-ю ошибку Bad Request. Добавьте, например, к URL-у что-то вроде goods/10/another_param и увидите ошибку в консоли и ответ 400 - кривой запрос не прошел.
По http-кодам ответов сервера
Мы не будем заморачиваться с выводом разных кодов, хотя по REST-у это и стоит делать.
Клиентских ошибок много. Даже в нашем простом случае уместна 405 в случае неправильно переданного метода.
Намеренно не хочу усложнять.
В случае успеха сервер у нас всегда вернет 200 ОК.
По хорошему, при создании ресурса стоит отдавать 201 Created.
Но опять-таки в плане упрощения эти тонкости мы отбросим, а в реальном проекте Вы их легко реализуете сами.
По совести говоря, статья закончена. Думаю, Вы уже поняли подход, каким образом разруливаются все маршруты, вынимаются данные, как это протестировать, как добавлять новые запросы и т.д. Но я для завершения образа приведу реализацию оставшихся 7 запросов, которые мы обозначили в начале статьи. Попутно приведу пару интересных замечаний, а в конце выложу архив с исходниками.
POST /goods
Добавление нового товара
// Добавление нового товара // POST /goods if ($method === "POST" && empty($urlData)) { // Добавляем товар в базу... // Выводим ответ клиенту echo json_encode(array("method" => "POST", "id" => rand(1, 100), "formData" => $formData)); return; }
urlData сейчас пустой, но зато используется formData - мы ее просто выведем клиенту.
Как сделать "правильно"?
Согласно канонам REST в post-запросе следует отдавать обратно только id созданной сущности или url, по которому эту сущность можно получить.
То есть в ответе будет или просто число - {goodId}
, или /goods/{goodId}
.
Почему я написал "правильно" в кавычках? Да потому, что REST - это набор не жестких правил, а рекомендаций.
И как будете реализовывать именно Вы, зависит от Ваших предпочтений или уже принятых соглашений на конкретном проекте.
Просто имейте в виду, что другой программист, читающий код и осведомленный о REST-подходе,
будет ожидать в ответе на post-запрос id созданного объекта или url, по которому можно get-запросом вытащить данные об этом объекте.
Тестим из консоли
$.ajax({url: "/examples/rest/goods/", method: "POST", data: {good: "notebook", price: 20000}, dataType: "json", success: function(response){console.log("response:", response)}})
Curl -X POST https://сайт/examples/rest/goods/ --data "good=notebook&price=20000" -i
PUT /goods/{goodId}
Редактирование товара
// Обновление всех данных товара // PUT /goods/{goodId} if ($method === "PUT" && count($urlData) === 1) { // Получаем id товара $goodId = $urlData; // Обновляем все поля товара в базе... // Выводим ответ клиенту echo json_encode(array("method" => "PUT", "id" => $goodId, "formData" => $formData)); return; }
Здесь уже все данные используются по-полной. Из urlData вытаскивается id товара, а из formData - свойства.
Тестим из консоли
$.ajax({url: "/examples/rest/goods/15", method: "PUT", data: {good: "notebook", price: 20000}, dataType: "json", success: function(response){console.log("response:", response)}})
Curl -X PUT https://сайт/examples/rest/goods/15 --data "good=notebook&price=20000" -i
PATCH /goods/{goodId}
Частичное обновление товара
// Частичное обновление данных товара // PATCH /goods/{goodId} if ($method === "PATCH" && count($urlData) === 1) { // Получаем id товара $goodId = $urlData; // Обновляем только указанные поля товара в базе... // Выводим ответ клиенту echo json_encode(array("method" => "PATCH", "id" => $goodId, "formData" => $formData)); return; }
Тестим из консоли
$.ajax({url: "/examples/rest/goods/15", method: "PATCH", data: {price: 25000}, dataType: "json", success: function(response){console.log("response:", response)}})
Curl -X PATCH https://сайт/examples/rest/goods/15 --data "price=25000" -i
К чему эти понты с PUT и PATCH?
Разве одного PUT не достаточно? Разве не выполняют они одно и то же действие - обновляют данные объекта?
Именно так - внешне действие одно. Разница в передаваемых данных.
PUT предполагает, что на сервер передаются все
поля объекта, а PATCH - только измененные
.
Те, которые переданы в теле запроса.
Обратите внимание, что в предыдущем PUT мы передали и название товара, и цену.
А в PATCH - только цену. То есть мы отправили на сервер только измененные данные.
Нужен ли Вам PATCH - решайте сами. Но помните о том читающем код программисте, о котором я упоминал выше.
DELETE /goods/{goodId}
Удаление товара
// Удаление товара // DELETE /goods/{goodId} if ($method === "DELETE" && count($urlData) === 1) { // Получаем id товара $goodId = $urlData; // Удаляем товар из базы... // Выводим ответ клиенту echo json_encode(array("method" => "DELETE", "id" => $goodId)); return; }
Тестим из консоли
$.ajax({url: "/examples/rest/goods/20", method: "DELETE", dataType: "json", success: function(response){console.log("response:", response)}})
Curl -X DELETE https://сайт/examples/rest/goods/20 -i
С DELETE-запросом все понятно. Теперь давайте рассмотрим работу с пользователями - роутер users и соответственно, файл users.php
GET /users/{userId}
Получение всех данных о пользователе. Если GET-запрос вида /users/{userId} , то мы вернем всю информацию о пользователе, если дополнительно указывается /info или /orders , то соответственно, только общую информацию или список заказов.
// Роутер function route($method, $urlData, $formData) { // Получение всей информации о пользователе // GET /users/{userId} if ($method === "GET" && count($urlData) === 1) { // Получаем id товара $userId = $urlData; // Вытаскиваем все данные о пользователе из базы... // Выводим ответ клиенту echo json_encode(array("method" => "GET", "id" => $userId, "info" => array("email" => "[email protected]", "name" => "Webdevkin"), "orders" => array(array("orderId" => 5, "summa" => 2000, "orderDate" => "12.01.2017"), array("orderId" => 8, "summa" => 5000, "orderDate" => "03.02.2017")))); return; } // Возвращаем ошибку header("HTTP/1.0 400 Bad Request"); echo json_encode(array("error" => "Bad Request")); }
Тестим из консоли
$.ajax({url: "/examples/rest/users/5", method: "GET", dataType: "json", success: function(response){console.log("response:", response)}})
Curl -X GET https://сайт/examples/rest/users/5 -i
GET /users/{userId}/info
Общая информация о пользователе
// Получение общей информации о пользователе // GET /users/{userId}/info if ($method === "GET" && count($urlData) === 2 && $urlData === "info") { // Получаем id товара $userId = $urlData; // Вытаскиваем общие данные о пользователе из базы... // Выводим ответ клиенту echo json_encode(array("method" => "GET", "id" => $userId, "info" => array("email" => "[email protected]", "name" => "Webdevkin"))); return; }
Тестим из консоли
$.ajax({url: "/examples/rest/users/5/info", method: "GET", dataType: "json", success: function(response){console.log("response:", response)}})
Curl -X GET https://сайт/examples/rest/users/5/info -i
GET /users/{userId}/orders
Получение списка заказов пользователя
// Получение заказов пользователя // GET /users/{userId}/orders if ($method === "GET" && count($urlData) === 2 && $urlData === "orders") { // Получаем id товара $userId = $urlData; // Вытаскиваем данные о заказах пользователя из базы... // Выводим ответ клиенту echo json_encode(array("method" => "GET", "id" => $userId, "orders" => array(array("orderId" => 5, "summa" => 2000, "orderDate" => "12.01.2017"), array("orderId" => 8, "summa" => 5000, "orderDate" => "03.02.2017")))); return; }
Тестим из консоли
$.ajax({url: "/examples/rest/users/5/orders", method: "GET", dataType: "json", success: function(response){console.log("response:", response)}})
Curl -X GET https://сайт/examples/rest/users/5/orders -i
Итоги и исходники
Исходники из примеров статьи -
Как видим, организовать поддержку REST API на нативном php оказалось не так уж и сложно и вполне законными способами. Главное - это поддержка маршрутов и нестандартных для php методов PUT, PATCH и DELETE.
Основной код, реализовывающий эту поддержку, уместился в 3 десятка строк index.php. Остальное - это уже обвязка, которую можно реализовать как угодно. Я предложил это сделать в виде подключаемых файлов-роутеров, имена которых совпадают с сущностями Вашего проекта. Но можно подключить фантазию и найти более интересное решение.
1 year ago | 9.8K
В программированию, очень часто встречается задача, когда нужно обратиться к другому сайту через HTTP или HTTPS. В этой статье мы рассмотрим простой способ, как с помощью языка программирования PHP выполнить данную задачу.
Для чего обращаться с помощью PHP через HTTP или HTTPS к другому сайту?
Причин может быть несколько, например, на вашем сайте, есть часть функционала, которая отвечает за добавление новых товаров или каталогов фильмов на ваш сайт.
Новые фильмы выходят на экран практически ежедневно и этот процесс лучше автоматизировать, чтобы этим занимался робот, который сделает это бесплатно.
С товарами, ситуация такая же - у вашего интернет-магазина могут быть партнеры, которые захотят разместить на вашем сайте свои товары и с каждой продажи товара, партнеры будут отдавать вам, часть своих доходов. Если у партнера несколько тысяч товаров и база постоянно обновляется, процесс добавления товаров на сайт также необходимо автоматизировать с помощью языка программирования PHP.
Пример обращения к другому сайту с помощью PHP
В этом простом примере, мы будем использовать стандартную функцию PHP под названием file_get_contents().
В ответ от сервера VK, вы увидите следующую информацию:
{ - response: [ - { - id: 210700286, - first_name: "Lindsey", - last_name: "Stirling", - bdate: "21.9.1986" - } - ] }
где, мы получили Имя, Фамилию и дату рождения пользователя с ID 210700286.
Как теперь мы может с помощью PHP получить эту информацию и преобразовать ее в массив, для удобной дальнейшей работы?
С помощью языка программирования PHP и функции file_get_contents(), это сделать очень просто!
$user_id - это переменная, в которую вы записываете ID пользователя VK,
$info - в этой переменной мы сохраняем результат обращения к API сайта VK.COM
Имея массив с этой информацией, вы можете на вашем сайте, отображать интересных вам пользователей, для какой-либо цели, а также с помощью , вы можете красиво оформить вывод данной информации на вашем сайте.
Вывод
Как вы видите, с помощью PHP вы можете очень легко делать запросы к HTTP и HTTPS сайтам и мы рассмотрели лишь одну функцию языка программирования PHP с помощью которой можно получить данные из внешнего сайта.
В следующих статьях, мы рассмотрим еще одну интересную, но более мощную функцию, в которую вы сможете задавать дополнительные параметры, такие как браузер, операционная система и другие, для более изящной работы с внешними сайтами.